
I am currently working on world models for robotics research and taking a gap year to pursue Ph.D. opportunities. If you find my background suitable for your research group, please feel free to contact me at longxhe@gmail.com.
My research primarily focuses on reinforcement learning, generative model, and optimization theory, currently, I am interested in
- GenAI for RL: Leveraging diffusion models to enhance RL performance.
- Robust RL: Designing policies resilient to corrupted data or adversarial environments.
- RL+X: Unlocking the potential of RL in other fields or using X to improve RL.
Specifically, I am interested in developing practically efficient algorithms with theoretical justification for fundamental machine learning problems.
I received my master’s degree from Tsinghua University in June 2025, where I was advised by Prof. Xueqian Wang (王学谦) in the Artificial Intelligence Program at Tsinghua Shenzhen International Graduate School. I also work closely with Prof. Li shen (沈力).
🔥 News
- 2025.09: 🎉 RPEX is accepted by NeurIPS 2025
- 2024.05: AlignIQL has been preprinted on arXiv
- 2024.04: DiffCPS has been preprinted on arXiv
📝 Publications
Reinforcement Learning
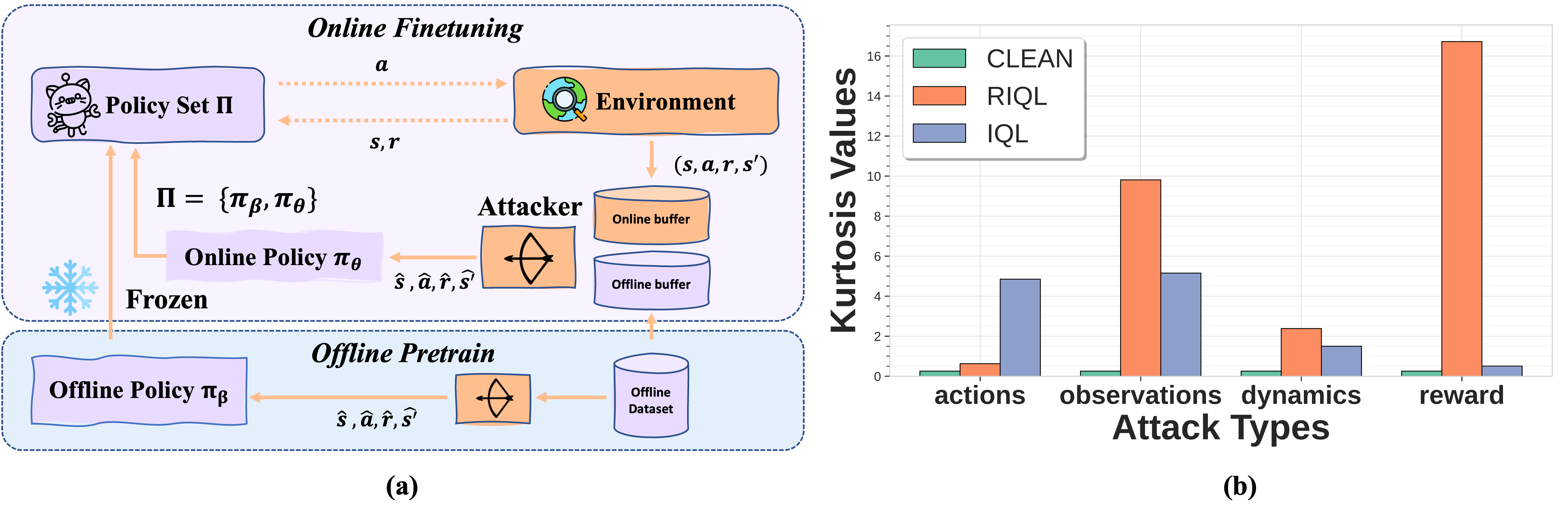
Robust Policy Expansion for Offline-to-Online RL
under Diverse Data Corruption
Longxiang He, Deheng Ye, Junbo Tan, Xueqian Wang, Li Shen
- We propose RPEX, an Offline-to-Online method that improves the performance of offline pre- trained RL policies under a wide range of data corruptions.
AlignIQL: Policy Alignment in Implicit Q-Learning through Constrained Optimization , Arxiv 2024, Longxiang He, Li Shen, Junbo Tan, Xueqian Wang
- TLDR: We introduce a new method (AlignIQL) to extract the policy from the IQL-style value function and explain when IQL can utilize weighted regression for policy extraction.
DiffCPS: Diffusion Model based Constrained Policy Search for Offline Reinforcement Learning, Arxiv 2024, Longxiang He, Li Shen, Linrui Zhang, Junbo Tan, Xueqian Wang
- TLDR: DiffCPS integrates diffusion-based policies into Advantage-Weighted Regression (AWR) via a primal-dual framework and offers insights into the advantages of employing diffusion models in offline decision-making, as well as elucidates the relationship between AWR and TD3+BC.
FOSP: Fine-tuning Offline Safe Policy through World Models, ICLR 2025, Chenyang Cao, Yucheng Xin, Silang Wu, Longxiang He, Zichen Yan, Junbo Tan, Xueqian Wang
🦉 Blogs
- 2022.10: 🎉 Transformer Attention Layer gradient The full derivation of Transformer attention gradient. We also compare the gradient we calculated with PyTorch to prove the correctness.
- 2022.08: 🎉 CNN Stochastic Gradient Descent The full derivation of CNN gradient.